
3D-CVF: Generating Joint Camera and LiDAR Features Using Cross-View Spatial FeatureFusion for 3D Object Detection - ECCV2020
https://arxiv.org/abs/2004.12636
0. 요약
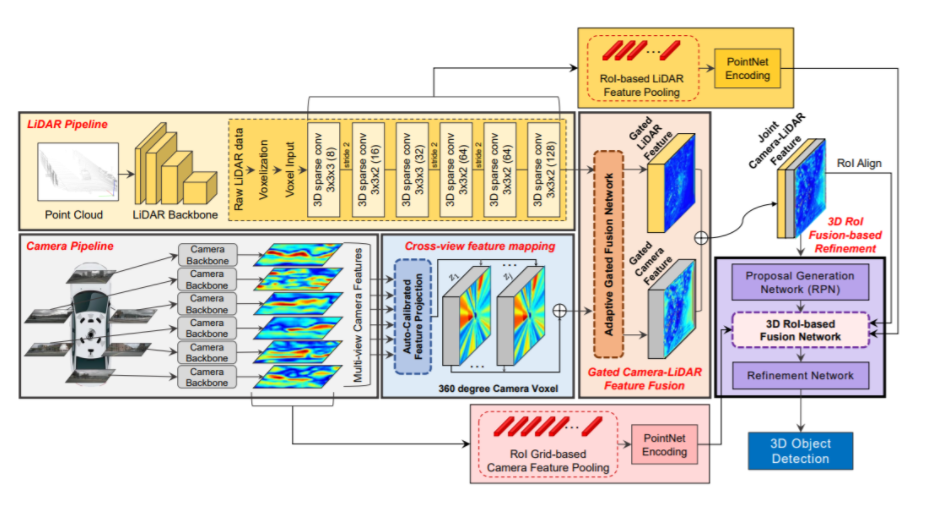
Lidar pipeline
라이다 데이터를 voxelization 한다. 이를 VoxelNet을 통해 encode, 6개의 sparse conv layer을 통해 최종적으로 BEV domain에서 128 channel의 feature를 얻음.
Camera pipeline
라이다 파이프라인과 병렬로 작동. 사전에 훈련된 ResNet-18과 FPN을 통해 256 channel의 feature를 얻음.
Cross-View Feature Mapping
이미지 프레인상의 feature를 BEV상의 feature로 transform(매핑) 하는 과정. auto-calibrated projection을 통해 camera feature를 BEV feature로 projection한다.
auto-calibrated projection: lidar의 voxel구조보다 x,y 축이 2배 더 큰 구조로하는 camera voxel 구조를 갖게하고, 이 voxel들의 중심을 world-to-camera-view projection matrix를 통해 이미지 feature의 (x,y)에 project시킨다. 이때, calibration offset (dx, dy)에 의해 (x+dx, y+dy)로 조정된다. 이 조정된 위치에 인접한 pixel들을 bilinear interpolation시켜 voxel에 interpolation값을 대입한다.
interpolation할때 weight는 (x+dx, y+dy)와 해당 픽셀과의 유클리디언 거리에 비례하고, 모든 weight의 합은 1이되도록 nomalization되어있다.
Gated Camera-Lidar Feature Fusion
projected camera feature와 lidar feature를 합치는 과정. 각 영역에서 camera feature와 lidar feature 둘 사이의 중요도 차이를 반영하여 합쳐짐. 이를 위해 adaptive gated fusion network를 사용.
adaptive gated fusion network는 attention map을 통해 각 영역에서의 camera와 lidar의 중요도를 판단하여 그 비율에 맞게 두 feature를 합침.
결과적으로 joint camera-lidar feature를 생성.
3D RoI Fusion-based Refinement
joint feature를 RPN을 이용해 region proposal를 수행하고 low-level lidar feature에서는 3D RoI pooling, low-level camera feature에는 3D Grid-based pooling을 통해 나온 각각의 feature를 joint feature와 합쳐 이를 사용하여 최종적으로 region proposal를 refinement한다.
low-level를 쓰는이유 : joint feature는 공간 정보가 부족하기 때문에 공간정보가 풍부한 low-level들을 사용한다.
3D Grid-based pooling : low-level camera feature에서 도메인이 달라(BEV도메인도 아니고 3D 데이터도아님) 바로 3D RoI pooling을 할 수 없음. 대신, region proposal box를 image plane에 투영시키고 이 점들과 대응되는 camera feature들을 PointNet을 통해 encode함.
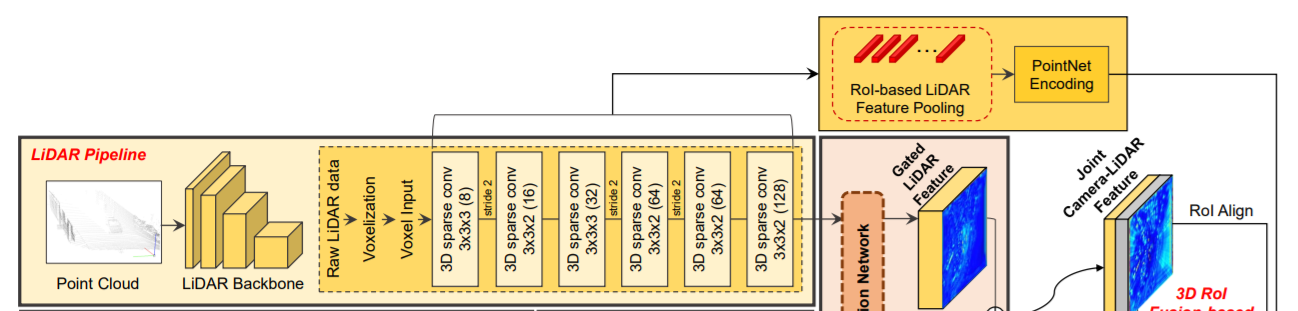
3.1 Overall architecture
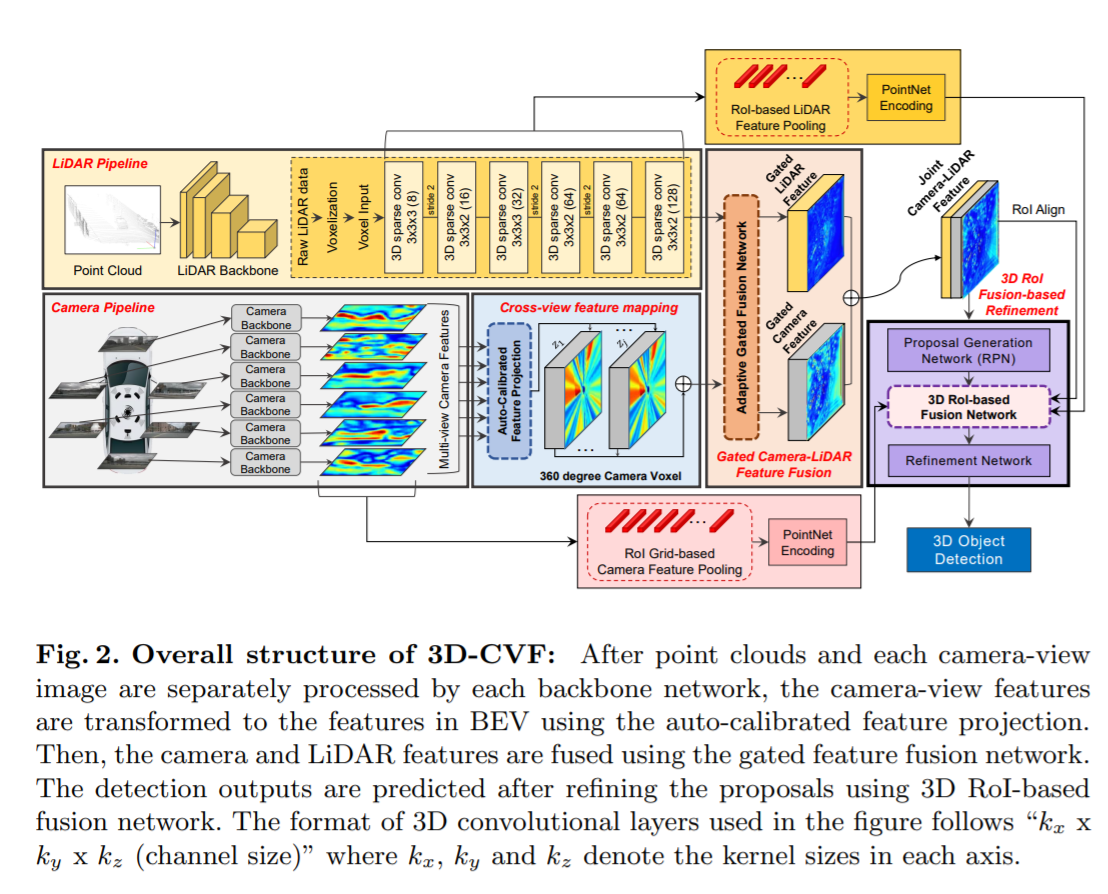
1) 라이다 파이프라인, 2) 카메라 파이프라인, 3) cross-view spatial feature mapping, 4) gated camera-lidar feature fusion network, 5) proposal generation and refinement network 5가지로 구성되어있다.
라이다 파이프라인: 라이다의 점들은 먼저 라이다 voxel 구조를 기반으로 구성된다. 각 voxel 안의 라이다 점들은 고정 길이의 embedding vector를 만들어내는 point encoding network(Voxelnet: End-to-end learning for point cloud based 3d object detection.)에 의해 encode된다. encode된 라이다 voxel들은 stride가 2인 6개의 3D sparse convolution 레이어(Second: Sparsely embedded convolutional detection.)에 의해 처리되어 BEV 도메인에서의 128채널의 라이다 feature를 만들어낸다. sparse convolution 레이어를 적용한 라이다 feature map의 width 와 height는 라이다 voxel structure 것보다 8배 축소 된다.
RGB 파이프라인(카메라 파이프라인): 라이다 파이프라인과 병렬적으로, 카메라 RGB 이미지는 CNN backbone network에 의해 처리된다. pre-trained된 ResNet-18 이후에 feature pyramid network(FPN)를사용하여 카메라-뷰로에 표시되는 256채널의 camera feature map을 만들어낸다. camera feature map의 width와 height는 input RGB image보다 8배 축소된다.
Cross-View Feature Mapping: cross-view feature(CVF) 매핑은 BEV에 투영된 카메라 feature를 만든다. auto-calibrated projection은 카메라뷰안의 카메라 feature map을 BEV에서의 feature map으로 변환시킨다. 그리고나서, 투영된 feature map 은 추가적인 conv layer에 의해 강화되고 gate camera-lidar feature fusion 단계로 전달된다.
(camera feature를 BEV domain lidar feature 좌표계로 옮기는 과정)
Gated Camera-Lidar Feature Fusion: 카메라 feature map과 lidar feature map을 결합하기 위해 adaptive gated fusion network를 사용하였다. 각 modality(카메라 feature & 라이다 feature)의 중요도에 따라 기여도를 조정하기 위해 두 feature map에 spatial attention map이 적용된다. adaptive gated fusion network는 joint camera-lidar feature map을 만들어내고, 이를 3D RoI fusion-based refinement 단계로 전달한다.
3D RoI Fusion-based Refinement: joint camera-lidar feature map을 바탕으로 region proposal이 생성된 후에, 적절한 개선(refine)을 위해 RoI pooling이 적용된다. joint camera-lidar feature map은 충분한 공간 정보를 가지고 있지 않기떄문에, 3D RoI-based pooing를 사용해 multi-scale lidar feature와 camera feature를 추출한다. 이 feature들은 PointNet encoder에 의해 각각 encode되어지고 3D RoI기반의 fusion network를 통해 joint camera-lidar feature map과 융합된다. 융합된 feature는 최종 detection 결과를 만들어내는데 사용된다.
3.2 Cross-View Feature Mapping
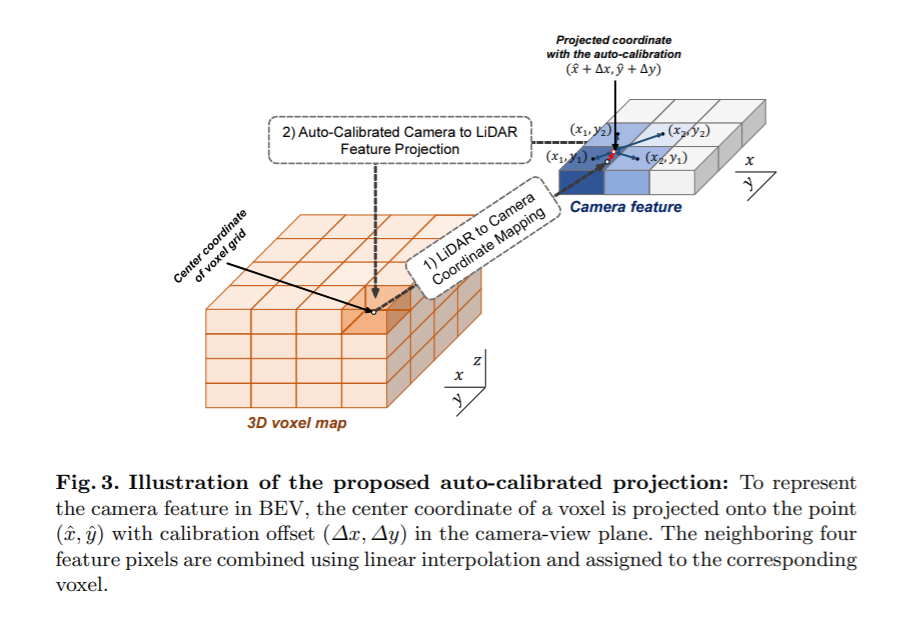
Dense Camera Voxel Structure: feature mapping(BEV에 투영된 feature를 만들기 위한 mapping)을 위해 카메라 voxel구조를 사용했다. 공간적으로 빽빽한 feature를 만들기 위해, width와 height가 라이다 voxel 구조의 (x,y)축보다 2배 더 긴 camera voxel 구조를 설계하였다. 이것은 voxel 구조가 더 높은 공간적 resolution을 갖게한다. 우리의 설계를 통해, camera voxel 구조는 라이다 voxel 구조보다 4배 더 많은 voxel를 갖는다.
(아래 auto-calibrated projection에서 설명하는 BEV feature의 voxel 구조를 camera voxel라고 하지않았나 싶다.)
Auto-Calibrated Projection method(자동으로 보정되는 투영 방법): 다음과 같은일을 위해 auto-calibrated projection 이 고안되었다. 1) camera-view feature를 BEV feature로 변환 2) camera-view feature 와 BEV feature간의 최고의 correspondence를 찾아 정보 fusion효과를 극대화. 우선, voxel의 중심은 world-to-camera-view projection matrix를 통해 camera-view plane의 (x,y)로 투영되고 투영된 (x,y)는 calibration offset(∆x, ∆y)에 의해 조정된다. 그러고나서, calibrate된 (x + ∆x, y + ∆y) 위치 주변의 이웃 camera feature 픽셀들이 interpolation 방법에 의해 결정된 weight와 함께 합쳐진다(combine). 즉, combine된 픽셀 벡터 u는 다음과 같다.
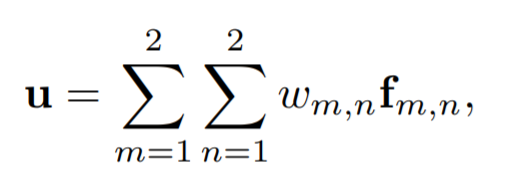
f m,n : (x + ∆x, y + ∆y)의 4개의 이웃 feature pixel들
w m,n : interpolation 방법으로 얻은 weight
bilinear interpolation을 통해, w m,n은 다음과 같이 유클리디언 거리를 통해 얻어진다.
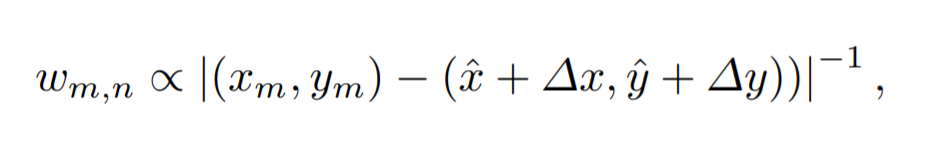
이때, w m,n 4개를 모두 더했을 때 1이되도록 nomalized 해준다.
그리고나서, combine된 feature u는 대응되는 voxel에 할당된다. 서로다른 calibration offset(∆x, ∆y)은 3D 공간의 다른 영역에 할당된다. 이 calibration offset 파라미터는 다른 네트워크 weight와 함께 같이 최적화 할 수 있습니다. auto-calibrated projection은 BEV 도메인에서의 lidar feature map과 가장 잘 매치(match)되는 공간적으로 smooth 한 camera feature map을 제공한다.
3.3 Gated Camera-LiDAR Feature Fusion
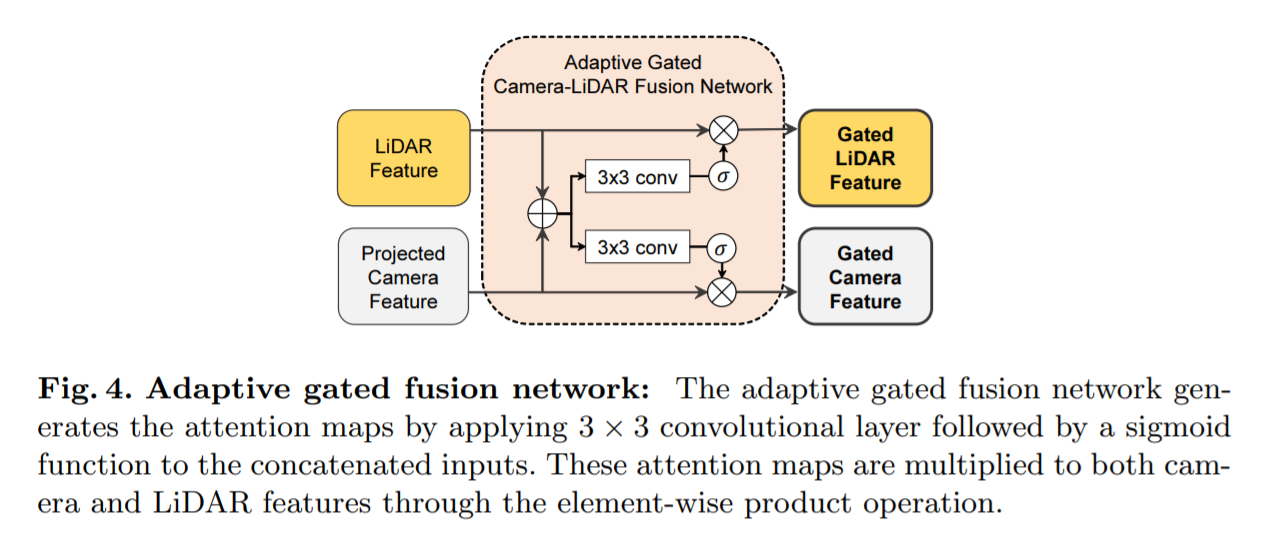
Adaptive Gated Fusion Network: 카메라와 라이다 센서로부터 주요한 feature를 뽑아내기 위해, object detection task와의 연관성을 바탕으로 feature를 선택적으로 결합시키는 adaptive gated fusion network를 적용하였다(Robust deep multimodal learning based on gated information fusion network.). 카메라와 라이다 feature들은 다음과 같이 attention map을 사용하여 gate(논리게이트)된다.
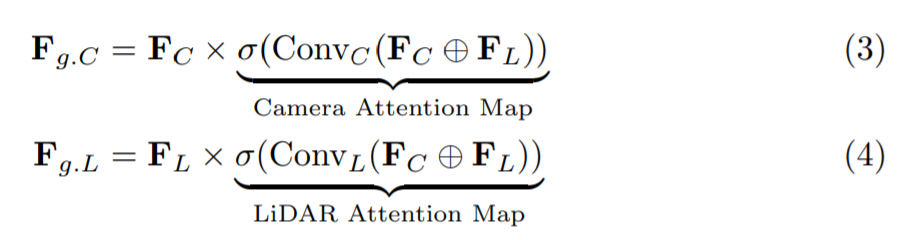
F C, F L : 카메라 feature, 라이다 feature
F g.C, F g.L : 대응되는 게이트된 feature
x : element-wise product
+ : channel-wise concatenation
attention map의 요소들은 카메라와 라이다 feature의 상대적인 중요도를 나타낸다. attention map이 적용된 후, 최종 joint feature F joint는 F g.C와 F g.L의 channel-wise concatenating을 통해 얻어진다.
(Introduction에서도 말했듯이 3D detection task에서 라이다 데이터의 중요도가 너무 높아서 단순히 두 센서의 feature을 concat하게되면 네트워크가 라이다 데이터만 사용하게 되어 오히려 안쓰느니만 못한 결과를 얻게 된다. 그러나 라이다 데이터의 경우 거리가 멀면 sparse해진다는 단점이 있고 object의 confidence를 판단하는데 있어서 카메라 feature가 도움을 줄 수 있는 부분이 있는데 어떻게하면 네트워크가 카메라 데이터를 사용할 수 있을지에 대해 고민하였고 그에 대한 해답으로 나온 Network가 Adaptive Gated Fusion Network이다.)
3.4 3D-RoI Fusion-based Refinement
Region Proposal Generation
초기의 detection결과는 RPN을통해 얻어진다. 초기의 regression 결과와 objectness scores는 결합된 카메라-라이다 feature에 detection sub-network을 적용함을써 값을 예측한다.
초기의 detection 결과는 objectness 점수와 관련된 많은 수의 proposal box들을 가지기 때문에, IoU threshold 0.7을 적용한 NMS 후처리를 적용시켜 objectness 점수가 높은 박스만 남게한다.
3D RoI-based Feature Fusion
예측된 box regression 값들은 rotated 3D RoI alignment를 통해 global coordinates로 translate된다.
(rotated 3D RoI alignment : Multi-task multi-sensor fusion for 3d object detection.)
low-level 라이다 feature와 카메라 feature들은 3D RoI-based pooling을 통해 pool되고 joint camera-lidar feature와 결합된다. 이 low-level feature들은 object들의 자세한 공간 정보(특히 z축)들을 보존하므로 region proposal을 refine하는데 유용한 정보를 제공하게된다.
구체적으로, 3D RoI box들에 연관되는 6개의 multi-scale 라이다 feature들은 3D RoI기반의 pooling에 의해 pool됩니다.
(RoI pool, RoI align : https://throwexception.tistory.com/1259)
이 low-level 라이다 feature들은 각 scale마다 PointNet encoders에 의해 encode 되고 1x1 feature vector로 연결되어진다.
(각 스케일의 feature를 pooling 한 후 PointNet encoder를 통과시켜 1x1 feature vector를 만들고 이를 모두 연결시킴)
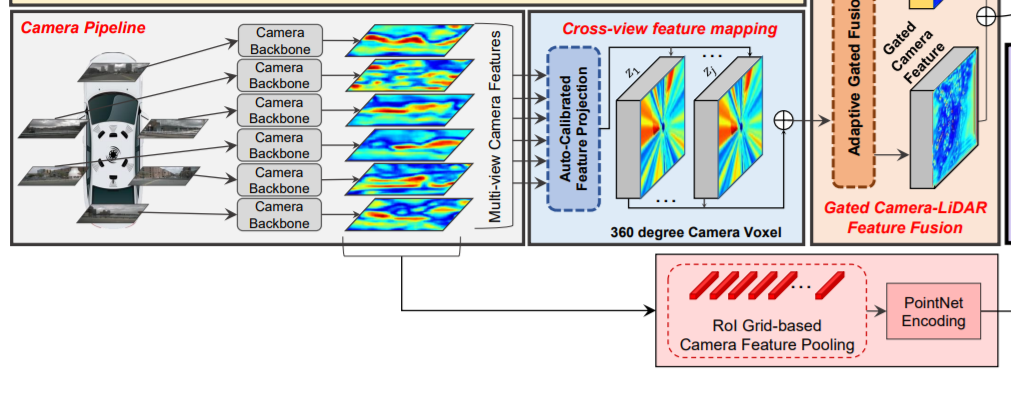
(multi-view camera feature : 여러 곳에서 촬영된 이미지들 각각의 feature)
동시에, multi-view camera feature들 또한 1x1 feature vector로 변형된다.
camera-view feature들은 3d RoI boxd와 다른 domain에서 표현되어 지기때문에 우리는 RoI grid-based pooling을 고안했다.
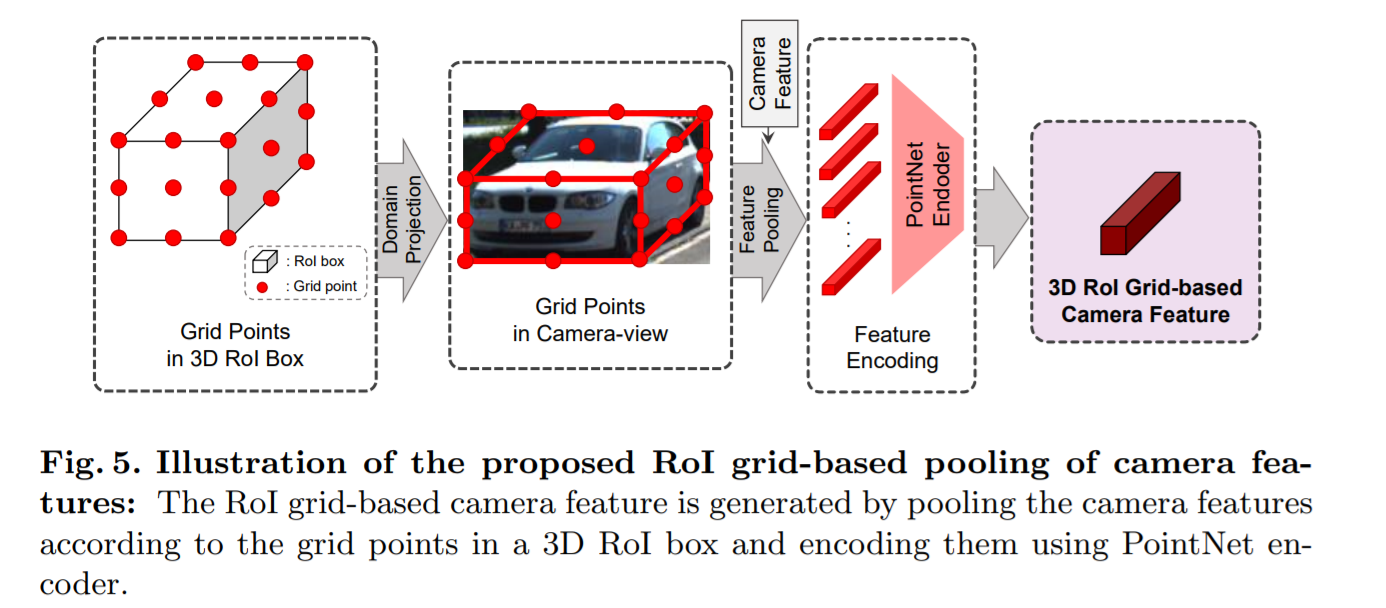
r x r x r 의 3D RoI box를 생각해보자. 이 포인트들은 camera view-domain으로 project되고 이 point들과 연관된 (corresponding) camera feature의 pixel들은 PointNet encoder에 의해 encode된다. 이 encode된 multi-view camera feature들의 연결(concatenation)은 또 다른 1x1 feature vector를 형성한다.
(예측한 bounding box를 균등하게 r×r×r 의 grid로 나눈 후 각 grid point를 camera 좌표계로 projection한 후 해당되는 camera feature를 grid point로 다시 가져온다. 이후 PointNet 기반의 encoder을 사용해 3D RoI Grid-based Camera Feature을 만들게 되고 이를 rotated 3D RoI alignment한 feature와 같이 이용한다.)
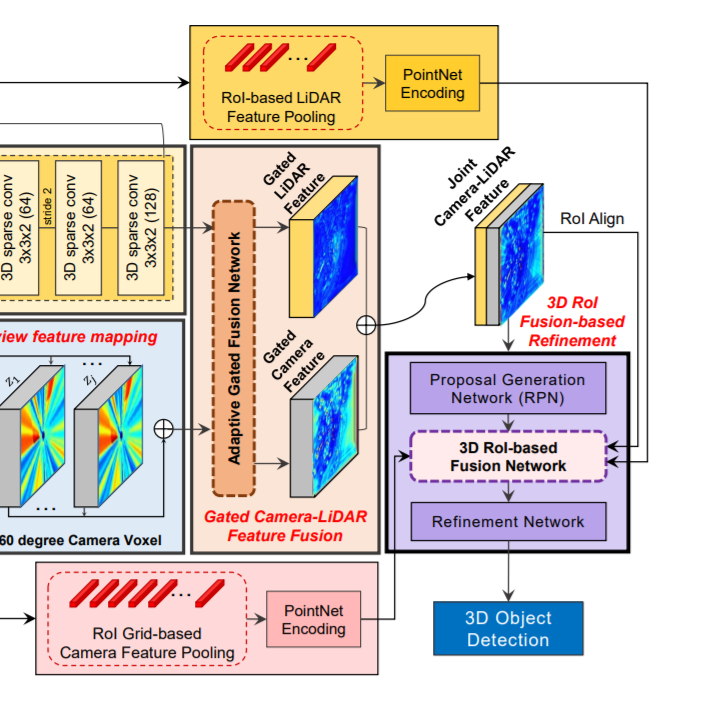
이 두개의 1x1 feature vector(low level 카메라, low level lidar)과 RoI aligned된 joint camera-lidar feature이 연결하여 proposal refinement에 사용되는 최종 feature가 만들어진다.
--------------------------
Voxel : https://limhyungtae.github.io/2021-09-12-ROS-Point-Cloud-Library-(PCL)-5.-Voxelization/
FPN : https://herbwood.tistory.com/18
Voxelnet: End-to-end learning for point cloud based 3d object detection.
Second: Sparsely embedded convolutional detection.
Robust deep multimodal learning based on gated information fusion network.
rotated 3D RoI alignment : Multi-task multi-sensor fusion for 3d object detection.
RoI pool, RoI align (from fast R-CNN): https://throwexception.tistory.com/1259
'논문 리뷰 > Computer Vision' 카테고리의 다른 글
| 3D-CVF 요약 (0) | 2022.02.25 |
|---|---|
| PointPillars 요약 (0) | 2022.02.22 |
| SASA 요약 (0) | 2022.02.22 |
| SECOND 요약 (0) | 2022.02.20 |
| VoxelNet 요약 (0) | 2022.02.19 |

댓글